How Often Is AI Wrong? A Practical Guide to Building Reliable Production-Ready AI-Models

Summary:
“How often is AI wrong?” It’s a deceptively simple question, yet one that hides a complex web of considerations, caveats, and real-world surprises.
In an age where we increasingly entrust decisions, from medical diagnoses to legal briefs, from customer-service chatbots to autonomous driving systems, to artificial intelligence, the question of how reliable these systems truly are matters more than ever.
We hear glowing success stories of AI breakthroughs. But equally, we see embarrassing missteps: models hallucinating plausible-but-false facts; image-recognition systems biased by demographic skew; decision-support tools misclassifying rare cases.
These failures raise a vital point: what is the error rate of AI systems in practice, and how do we build them so they are production-ready, dependable, and trustworthy?
This blog explores how often AI gets it wrong, why errors occur, and how to build reliable, real-world AI systems through practical strategies and case-backed insights.
Key Takeaways
- Error is inevitable: Even the best AI models have non-zero error rates; the question is how much and what kind.
- Context matters: The acceptable error threshold for an AI model depends heavily on domain (healthcare vs. chatbots) and risk tolerance.
- Monitoring and maintenance matter more than just initial development: Production-ready models require continuous evaluation, drift detection, and corrective processes.
- Transparency and governance build trust: Being clear about performance metrics, failure modes, and fallback procedures is key to reliability and user confidence.
- Building for reliability is not just a technical task; it’s organisational: Data pipelines, model lifecycle, human-in-the-loop design, and operational readiness all play a role.
Why Does This Question Matter: How Often Does AI Make Mistakes?
At first glance, the question “How often is AI wrong?” may seem academic. But in real-world applications, the cost of AI error can range from minor inconvenience to serious harm.
Consider: in healthcare, a mis-classification could lead to a wrong treatment; in law, a hallucinated fact could lead to a malpractice suit; in finance, a misprediction could cost millions.
Therefore, asking what the accuracy of AI systems is or how many errors AI makes is not just about metrics; it’s about trust, safety, governance, and responsibility.
When deploying models in production, especially in regulated industries, questions like how reliable AI is and how well it aligns with enterprise AI development standards become central.
Does the model meet a minimum acceptable error threshold? Are users aware of the error rate and limitations?
Are fallback/override procedures in place? With growing regulation, organisations are being held accountable not just for model performance, but for error transparency, bias mitigation, auditability, and monitoring.

How Often Is AI Wrong: Domain-By-Domain Statistics and Real-World Data?
The frequency of AI errors depends on the domain, model type, and context, but leveraging AI agent benefits, such as automation, accuracy, and adaptive learning, can greatly reduce errors and enhance overall reliability.
Healthcare
Note: These figures suggest that even in high-stakes domains like medicine, error rates of 5–20% are realistic depending on context.
Legal / Knowledge Work
Note: These error rates are alarmingly high for legal/knowledge work, where factual accuracy is critical.
Generative AI / LLMs / Search & Information Retrieval
A 2024 study found hallucination rates in generative LLMs (regarding references) were substantial.
Case Studies
Case Study 1: Legal Research AI & Hallucination
In Mata v. Avianca Inc. (S.D.N.Y., 2023), two lawyers used ChatGPT for legal research and unknowingly submitted a court brief citing six non-existent cases fabricated by the AI.
When the court verified the references, it found that every cited authority was fake.
The attorneys were fined $5,000 and publicly reprimanded.
This case underscored how over-reliance on generative AI without human validation can severely damage credibility and trust in AI systems.
Case Study 2: Production-drift & Model Maintenance
According to IBM:
For example, imaging AI might perform well in hospital A but degrade in hospital B with different devices.
Lessons learned:
- Building production-ready models requires not only initial validation, but post-deployment monitoring and maintenance.
- Organisations must invest in continuous evaluation, drift detection, logging of errors, and a pipeline for re-training.
Why AI Goes Wrong: Root Causes of Errors in AI Models?
Below are some primary drivers of error.
Data Quality & Bias
- Poor, incomplete, or non-representative training data lead to model misgeneralisation.
- Bias in data leads to systematic errors.
- Label noise or mis-annotation also increases error rates.
Domain shift / Deployment mismatch
- Models trained on one population or environment may fail when data distribution changes.
- When production data diverges from training data, error rates increase.
Model complexity / Over-fitting vs Under-fitting
- Over-fitted models may perform well in training/validation but poorly in production.
- Under-fitting leads to high baseline error.
- Both lead to a higher machine learning error rate than anticipated.
Algorithmic limitations, hallucinations & reasoning failures
- Especially for generative and reasoning AI, hallucinations are a major error mode: plausible but false output.
- Some theoretical work suggests that calibrated language models must hallucinate at a non-zero rate given statistical constraints.
- Models may lack domain knowledge, or context may be ambiguous.
Integration & Operational factors
- Even a good model can fail if deployed in a flawed pipeline.
- Automation bias occurs when humans over-trust AI outputs and fail to check when the AI is wrong.
- Lack of monitoring, absence of error-logging, and absence of fallback mechanisms amplify failure risk.
Building Production-Ready & Reliable AI Models: A Practical Guide
Let’s turn to the practical question: How do you build an AI model that is production-ready, reliable, and trusted?
Step 1: Define clear performance and error-threshold goals
- Establish the acceptable error threshold for your domain. Ask: What error rate is tolerable? What error types are unacceptable?
- Benchmark human performance if applicable, and set a target for your model (often equal or better than human, or at worst equivalent with strong oversight).
- Use domain-specific metrics: precision, recall, F1-score, false-positive rate, and false-negative rate.
- For generative models: hallucination rate, factual accuracy, citation accuracy.
Step 2: Data and training process
- Ensure your data is high quality, well-labelled, representative of the production environment, covers edge cases, and diverse.
- Perform data audits for bias, demographic coverage, missing data, and class imbalance.
- Use cross-validation, hold-out test sets, and, if possible, out-of-distribution test sets to simulate a real production shift.
- Build for robustness during data augmentation, simulate variation, and emphasize rare classes if risk-critical.
Step 3: Model evaluation & validation
- Use CA on the confusion matrix and performance metrics to deeply understand the error breakdown.
- Analyse error modes (which classes are mis-classified? false positives vs false negatives?).
- For generative AI, evaluate the hallucination rate, factual accuracy, and citation correctness.
Example: one study found 61.6% of citations in an LLM test were inaccurate.
- Use domain experts in evaluation loops for high-stakes applications.
Step 4: Deployment readiness & monitoring
- Develop logging of predictions, inputs, confidence scores, and error events.
- Build dashboards and alerts for drift detection (distribution changes), performance decay.
- Implement a human-in-the-loop (HITL) system, especially for edge cases or high-risk decisions.
- For generative models, include content verification / human review/fallback procedures for unverifiable outputs.
Step 5: Explainability, transparency & trust
- Implement explainability (XAI) so users can understand model reasoning.
- Provide documentation: model limitations, training data description, error rates, and known failure modes.
- Encourage users to verify high-impact outputs, and design UI to discourage over-trust of AI.
- Use disclaimers, request human verification in critical workflows.
Step 6: Maintenance, drift & lifecycle management
- Continuously monitor production performance. If error rates creep up, trigger an investigation.
- Re-train or fine-tune when distributions shift.
- Update models and pipelines as business/data context evolves.
- Periodically audit for bias, performance across sub-populations, and edge cases.
- Adopt governance frameworks: model versioning, change logs, audit trails.
Step 7: Governance, audit & regulatory compliance
- Align with standards: NIST AI Risk Management Framework, IEEE standards for trustworthy AI, ISO efforts around AI system reliability.
- Document error rates, risk assessments, and mitigation strategies.
- In regulated industries (healthcare, finance, legal), pursue certification or compliance with sector-specific regulations (FTC oversight, U.S. AI Regulations and Frameworks).
- Create an audit function for AI behaviour; error logs, incident reviews, and root-cause analysis when things go wrong.
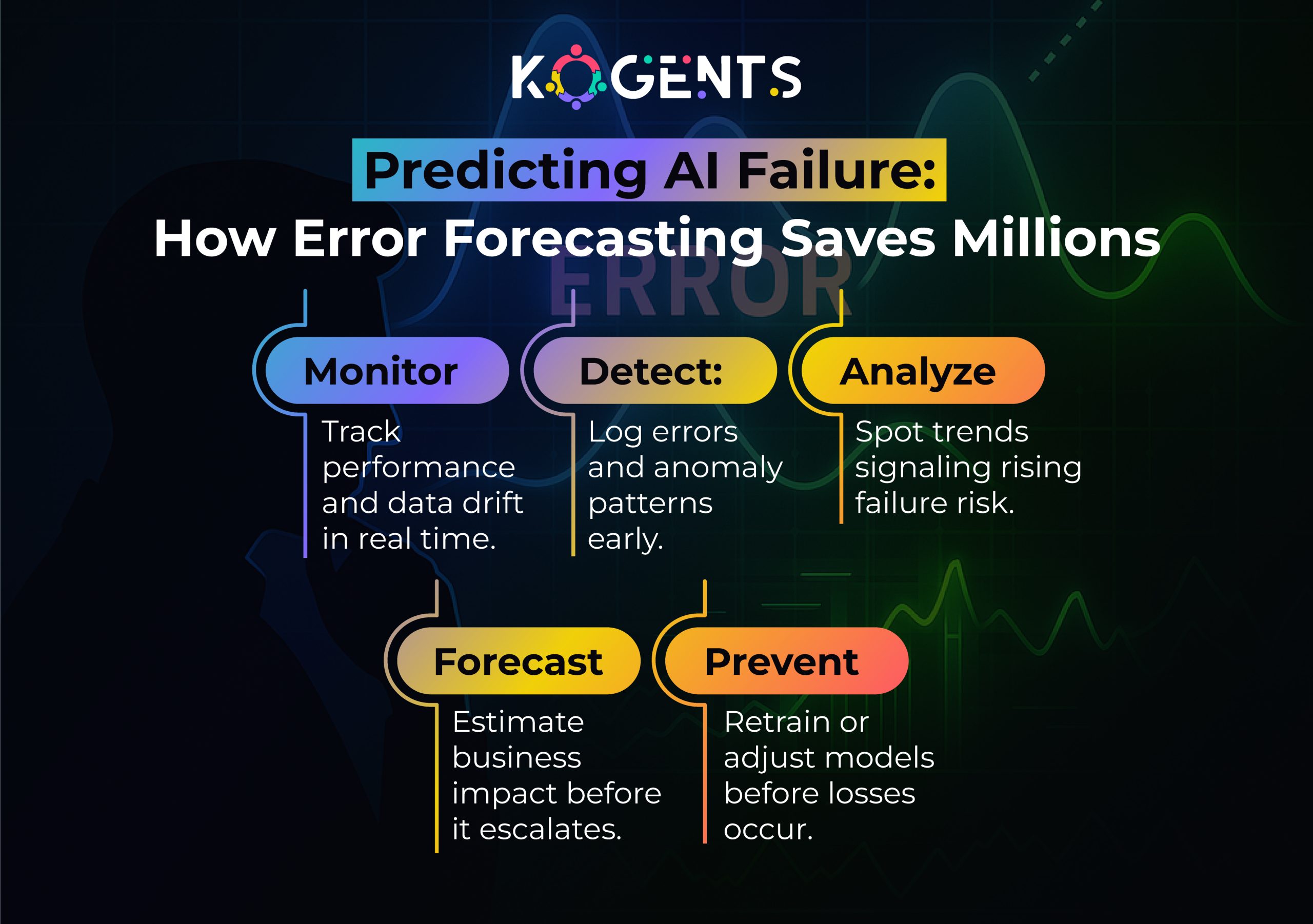
Table: Comparison of AI Error Rates & Context Across Domains
Conclusion
If you’re building or deploying an AI model, treat the question of how often is AI wrong and how frequently it makes mistakes as central, not only at development time, but as an ongoing operational metric.
Use the frameworks above, data quality, evaluation metrics, deployment readiness, monitoring, explainability, and governance, as your blueprint for building truly production-ready, trustworthy AI.
At Kogents.ai, we specialise in building AI systems that don’t just perform well in the lab; they stay robust, reliable, and intelligent in production.
As the best agentic AI company, we believe AI reliability isn’t just a feature; it’s a business-critical capability that defines long-term success.
FAQs
What is the typical error rate of AI systems?
There is no single “typical” error rate because it depends on domain, task complexity, model maturity, and data quality. In healthcare diagnostic AI, you might see error rates of 10%, in generative LLM tasks, you might see hallucination rates of 30–60%+.
Why does artificial intelligence make mistakes?
Mistakes may arise due to poor training data, domain or distribution shift when the production context differs from training, algorithmic limitations, model over-fitting or under-fitting, lack of human-in-loop verification, and opacity/automation bias where users rely uncritically on model outputs.
How reliable is AI in practice?
Reliability depends on how well the system is built, deployed, and monitored. A well-designed AI pipeline with robust data, monitoring, ground-truth checking, and human fallback can achieve high reliability (low error) in constrained tasks. But in open-ended or complex tasks, reliability can be much lower.
How many errors does AI make?
The numerical count depends on the volume of predictions and the error rate. If a model has a 10% error rate and processes 1 million cases, you’d expect 100,000 errors. But more important than raw count is the type of errors, their impact, and whether you have a mechanism to flag and rectify them.
What are AI hallucinations, and how often do they occur?
AI hallucinations refer to outputs that are plausible-looking but factually incorrect, fabricated, or unsupported. Occurrence varies: e.g., one study found ~61.6% of generated references were erroneous.
Kogents AI builds intelligent agents for healthcare, education, and enterprises, delivering secure, scalable solutions that streamline workflows and boost efficiency.